
Enabling bipedal walking robots to learn how to maneuver over highly uneven, dynamically changing terrains is challenging due to the complexity of robot dynamics and interacted environments. Recent advancements in learning from demonstrations have shown promising results for robot learning in complex environments. While imitation learning of expert policies has been well-explored, the study of learning expert reward functions is largely under-explored in legged locomotion. This paper brings state-of-the-art Inverse Reinforcement Learning (IRL) techniques to solving bipedal locomotion problems over complex terrains. We propose algorithms for learning expert reward functions, and we subsequently analyze the learned functions. Through nonlinear function approximation, we uncover meaningful insights into the expert’s locomotion strategies. Furthermore, we empirically demonstrate that training a bipedal locomotion policy with the inferred reward functions enhances its walking performance on unseen terrains, highlighting the adaptability offered by reward learning.
Contribution
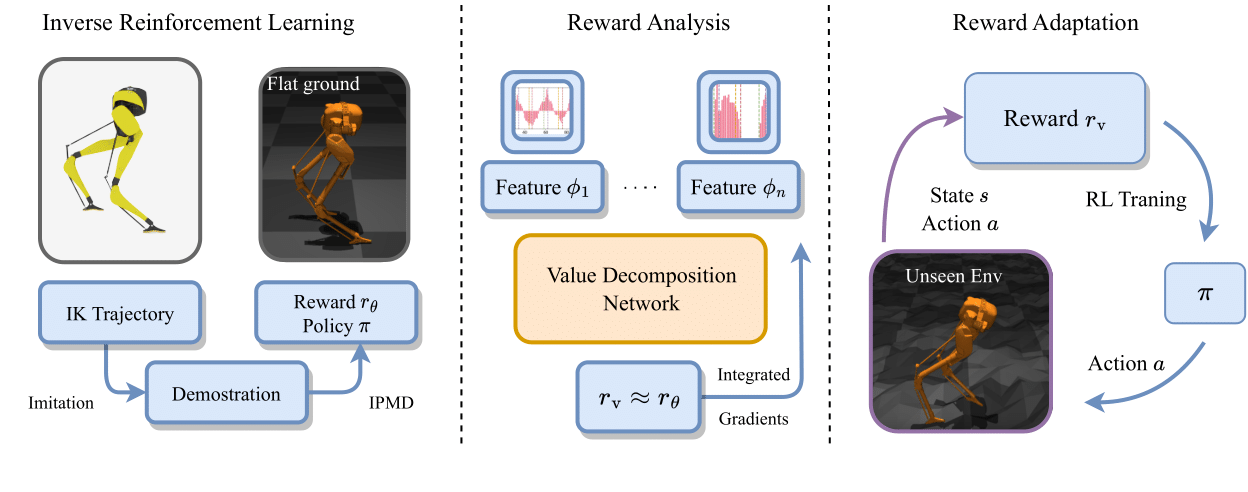
Inverse Reinforcement Learning for Bipedal Locomotion:
We propose a two-stage IRL paradigm to address bipedal locomotion tasks via IPMD.
In stage one, we obtain expert policies from a fully-body inverse kinematics function of Cassie. In the next stage, IPMD learns reward functions from the near-optimal demonstrations generated by the policies learned in the first stage.
Our work is the first study that applies IRL to bipedal locomotion under the average-reward criterion.
Importance Analysis of Expert Reward Function:
We employ a Value Decomposition Network (VDN) to approximate the inferred locomotion reward function and Integrated Gradients (IG) to analyze the VDN for reward interpretation. By ensuring the monotonicity of the feature space, VDN enables the interpretation of the reward function with IG while preserving model expressiveness. We successfully perform a rigorous analysis of the importance of individual features,
exposing components of the locomotion behavior that are crucial to its reward functions, thereby guiding the design of new rewards for new environments.
Reward Adaptation in Challenging Locomotion Environments:
We further verify that the learned reward from a flat terrain and the important features extracted from our reward analysis can be seamlessly adapted to novel, unseen terrains.
Our empirical results substantiate that the inferred reward function encapsulates knowledge highly relevant to robotic motions that are generalizable across different terrain scenarios.
Method
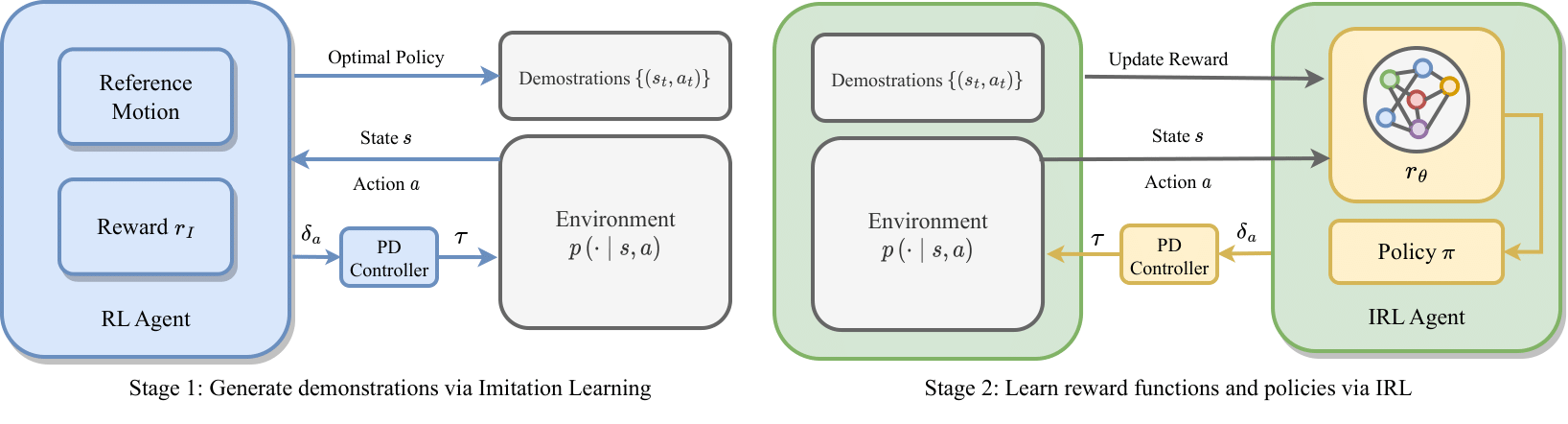
Stage 1 Train an imitation agent
We use Imitation Learning to train an agent to produce dynamically feasible demonstrations in MuJoCo.
Stage 2 Train IRL agent
We use IPMD to train an IRL agent based on the demonstrations generated in stage 1.
Results:
We generate a variety of uneven terrains in MuJoCo environments. The baseline agent manages to navigate these terrains, albeit in a less graceful manner with jerky motions. We find that incorporating the learned reward function from IRL significantly accelerates learning and produces more natural and robust locomotion behaviors, substantiating the transferability of the learned reward function across domains.
We observe that agents trained on diverse terrains display enhanced stability when deployed in unseen environments. For example, Cassie is able to navigate sinusoidal terrains with random height variations, without additional training. This corroborates the idea that the learned reward embodies a form of generalized knowledge beneficial for robotic locomotion across a range of terrain scenarios.
Representative Publications:
Wu, Feiyang, et al. “Infer and adapt: Bipedal locomotion reward learning from demonstrations via inverse reinforcement learning.” 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024.